Learn Hurst exponent for fractional Brownian Motion¶
This example performs to task of predicting Hurst exponent given the synthetic data generated from fractional Brownian motion.
import equinox as eqx
import fbm
import jax
import jax.numpy as jnp
import jax.random as jrandom
import matplotlib.pyplot as plt
import nets
import optax # https://github.com/deepmind/optax
jax.config.update("jax_platform_name", "cpu")
n_paths_train = 200
n_paths_test = 50
dt = 1e-2 / 3.0 # 300 time steps
hurst_exponent = jnp.around(jnp.linspace(0.2, 0.8, 7), decimals=7).tolist()
def dataloader(arrays, batch_size, *, key):
# this taken from equinox documentation
dataset_size = arrays[0].shape[0]
assert all(array.shape[0] == dataset_size for array in arrays)
indices = jnp.arange(dataset_size)
while True:
perm = jrandom.permutation(key, indices)
(key,) = jrandom.split(key, 1)
start = 0
end = batch_size
while end < dataset_size:
batch_perm = perm[start:end]
yield tuple(array[batch_perm] for array in arrays)
start = end
end = start + batch_size
def generate_data(key):
train_key, test_key = jrandom.split(key)
X_train, Y_train = [], []
X_test, Y_test = [], []
# generate train
for hurst in hurst_exponent:
train_key, _ = jrandom.split(train_key)
X = fbm.generate_fbm(
hurst=hurst,
n_paths=n_paths_train,
dt=dt,
key=train_key,
)
Y = jnp.array([hurst] * n_paths_train)
X_train.append(X)
Y_train.append(Y)
# generate test
for hurst in hurst_exponent:
test_key, _ = jrandom.split(test_key)
X = fbm.generate_fbm(
hurst=hurst,
n_paths=n_paths_test,
dt=dt,
key=test_key,
)
Y = jnp.array([hurst] * n_paths_test)
X_test.append(X)
Y_test.append(Y)
X_train = jnp.concatenate(X_train)
Y_train = jnp.concatenate(Y_train)
X_test = jnp.concatenate(X_test)
Y_test = jnp.concatenate(Y_test)
return (
X_train[..., None],
Y_train[..., None],
X_test[..., None],
Y_test[..., None],
)
seed = 1234
key = jrandom.PRNGKey(seed)
data_key, loader_key, model_key = jrandom.split(key, 3)
X_train, Y_train, X_test, Y_test = generate_data(key=data_key)
model = nets.create_simple_net(
dim=1,
signature_depth=3,
augment_layer_size=(3,),
augmented_kernel_size=3,
mlp_width=32,
mlp_depth=5,
output_size=1,
final_activation=jax.nn.sigmoid,
key=model_key,
)
iter_data = dataloader((X_train, Y_train), batch_size=128, key=loader_key)
optim = optax.adam(learning_rate=1e-3)
opt_state = optim.init(eqx.filter(model, eqx.is_array))
@eqx.filter_value_and_grad
def compute_loss(model, x, y):
pred_y = jax.vmap(model)(x)
assert pred_y.shape[0] == y.shape[0]
return jnp.mean(jnp.square(pred_y - y))
@eqx.filter_jit
def make_step(model, x, y, opt_state):
loss, grads = compute_loss(model, x, y)
updates, opt_state = optim.update(grads, opt_state)
model = eqx.apply_updates(model, updates)
return loss, model, opt_state
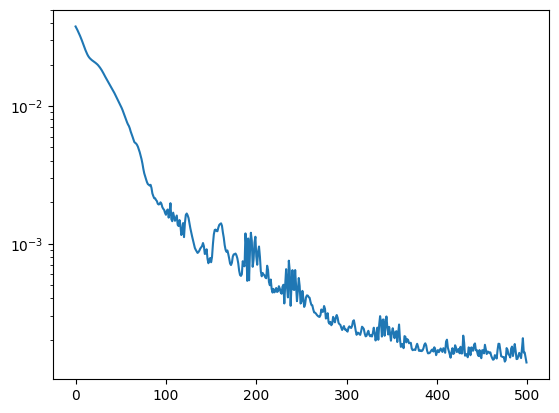
test_mse = []
for step, (x, y) in zip(range(500), iter_data):
loss, model, opt_state = make_step(model, x, y, opt_state)
loss = loss.item()
test_mse += [jnp.mean(jnp.square(jax.vmap(model)(X_test) - Y_test)).item()]
if step % 10 == 0:
print(f"step={step} \t loss={loss}")
step=0 loss=0.04216282069683075
step=10 loss=0.031003521755337715
step=20 loss=0.019243916496634483
step=30 loss=0.017822671681642532
step=40 loss=0.012136271223425865
step=50 loss=0.00992327369749546
step=60 loss=0.006969921290874481
step=70 loss=0.0047263759188354015
step=80 loss=0.0026983849238604307
step=90 loss=0.001573466695845127
step=100 loss=0.001687461044639349
step=110 loss=0.001219318131916225
step=120 loss=0.0020771166309714317
step=130 loss=0.0011161169968545437
step=140 loss=0.0007116930210031569
step=150 loss=0.000802830676548183
step=160 loss=0.0013996051857247949
step=170 loss=0.000989356660284102
step=180 loss=0.0007230553892441094
step=190 loss=0.0009078073780983686
step=200 loss=0.0009628456318750978
step=210 loss=0.0006351498886942863
step=220 loss=0.0005295654991641641
step=230 loss=0.0003828965709544718
step=240 loss=0.0005323939258232713
step=250 loss=0.0003383931762073189
step=260 loss=0.00038006779504939914
step=270 loss=0.00032600853592157364
step=280 loss=0.00029386597452685237
step=290 loss=0.0002725800150074065
step=300 loss=0.00022158370120450854
step=310 loss=0.00018463234300725162
step=320 loss=0.0002504262374714017
step=330 loss=0.00021754324552603066
step=340 loss=0.00017652346286922693
step=350 loss=0.0001712317462079227
step=360 loss=0.00019372034876141697
step=370 loss=0.00018393156642559916
step=380 loss=0.00013036229938734323
step=390 loss=0.0001685012102825567
step=400 loss=0.00012768665328621864
step=410 loss=0.00012908075586892664
step=420 loss=0.00012156621960457414
step=430 loss=0.0002003716945182532
step=440 loss=0.00013970596774015576
step=450 loss=0.0001433617144357413
step=460 loss=0.00010493868467165157
step=470 loss=0.00013489389675669372
step=480 loss=0.00012522486213129014
step=490 loss=0.00011203147005289793
plt.plot(test_mse)
plt.yscale("log")