Learn Hurst exponent for fractional Brownian Motion#
This example performs to task of predicting Hurst exponent given the synthetic data generated from fractional Brownian motion.
import equinox as eqx
import fbm
import jax
import jax.numpy as jnp
import jax.random as jrandom
import matplotlib.pyplot as plt
import nets
import optax # https://github.com/deepmind/optax
jax.config.update("jax_platform_name", "cpu")
n_paths_train = 200
n_paths_test = 50
dt = 1e-2 / 3.0 # 300 time steps
hurst_exponent = jnp.around(jnp.linspace(0.2, 0.8, 7), decimals=7).tolist()
def dataloader(arrays, batch_size, *, key):
# this taken from equinox documentation
dataset_size = arrays[0].shape[0]
assert all(array.shape[0] == dataset_size for array in arrays)
indices = jnp.arange(dataset_size)
while True:
perm = jrandom.permutation(key, indices)
(key,) = jrandom.split(key, 1)
start = 0
end = batch_size
while end < dataset_size:
batch_perm = perm[start:end]
yield tuple(array[batch_perm] for array in arrays)
start = end
end = start + batch_size
def generate_data(key):
train_key, test_key = jrandom.split(key)
X_train, Y_train = [], []
X_test, Y_test = [], []
# generate train
for hurst in hurst_exponent:
train_key, _ = jrandom.split(train_key)
X = fbm.generate_fbm(
hurst=hurst,
n_paths=n_paths_train,
dt=dt,
key=train_key,
)
Y = jnp.array([hurst] * n_paths_train)
X_train.append(X)
Y_train.append(Y)
# generate test
for hurst in hurst_exponent:
test_key, _ = jrandom.split(test_key)
X = fbm.generate_fbm(
hurst=hurst,
n_paths=n_paths_test,
dt=dt,
key=test_key,
)
Y = jnp.array([hurst] * n_paths_test)
X_test.append(X)
Y_test.append(Y)
X_train = jnp.concatenate(X_train)
Y_train = jnp.concatenate(Y_train)
X_test = jnp.concatenate(X_test)
Y_test = jnp.concatenate(Y_test)
return (
X_train[..., None],
Y_train[..., None],
X_test[..., None],
Y_test[..., None],
)
seed = 1234
key = jrandom.PRNGKey(seed)
data_key, loader_key, model_key = jrandom.split(key, 3)
X_train, Y_train, X_test, Y_test = generate_data(key=data_key)
model = nets.create_simple_net(
dim=1,
signature_depth=3,
augment_layer_size=(3,),
augmented_kernel_size=3,
mlp_width=32,
mlp_depth=5,
output_size=1,
final_activation=jax.nn.sigmoid,
key=model_key,
)
iter_data = dataloader((X_train, Y_train), batch_size=128, key=loader_key)
optim = optax.adam(learning_rate=1e-3)
opt_state = optim.init(eqx.filter(model, eqx.is_array))
@eqx.filter_value_and_grad
def compute_loss(model, x, y):
pred_y = jax.vmap(model)(x)
assert pred_y.shape[0] == y.shape[0]
return jnp.mean(jnp.square(pred_y - y))
@eqx.filter_jit
def make_step(model, x, y, opt_state):
loss, grads = compute_loss(model, x, y)
updates, opt_state = optim.update(grads, opt_state)
model = eqx.apply_updates(model, updates)
return loss, model, opt_state
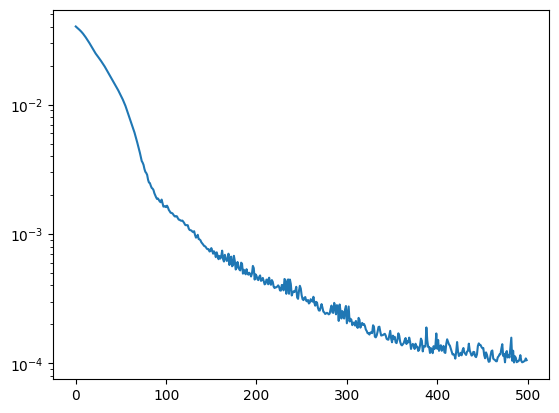
test_mse = []
for step, (x, y) in zip(range(500), iter_data):
loss, model, opt_state = make_step(model, x, y, opt_state)
loss = loss.item()
test_mse += [jnp.mean(jnp.square(jax.vmap(model)(X_test) - Y_test)).item()]
if step % 10 == 0:
print(f"step={step} \t loss={loss}")
step=0 loss=0.04126128554344177
step=10 loss=0.03442610800266266
step=20 loss=0.027970541268587112
step=30 loss=0.02049068734049797
step=40 loss=0.014842262491583824
step=50 loss=0.01463927049189806
step=60 loss=0.008735964074730873
step=70 loss=0.003853133413940668
step=80 loss=0.003183095483109355
step=90 loss=0.0017226741183549166
step=100 loss=0.0018800244433805346
step=110 loss=0.001246932428330183
step=120 loss=0.0010552150197327137
step=130 loss=0.0011177051346749067
step=140 loss=0.000960731296800077
step=150 loss=0.0007560451049357653
step=160 loss=0.0006463612080551684
step=170 loss=0.0007553484756499529
step=180 loss=0.0006547566154040396
step=190 loss=0.0005832638125866652
step=200 loss=0.0005575535469688475
step=210 loss=0.00035019911592826247
step=220 loss=0.00040039169834926724
step=230 loss=0.00045131167280487716
step=240 loss=0.0003143866779282689
step=250 loss=0.00036405035643838346
step=260 loss=0.0002983830636367202
step=270 loss=0.0002879722451325506
step=280 loss=0.000225563402636908
step=290 loss=0.00022640179668087512
step=300 loss=0.00024252216098830104
step=310 loss=0.00021433460642583668
step=320 loss=0.00020663876784965396
step=330 loss=0.0002086602326016873
step=340 loss=0.0001339660375379026
step=350 loss=0.0001248260377906263
step=360 loss=0.00014416594058275223
step=370 loss=0.0001910615392262116
step=380 loss=0.000121168268378824
step=390 loss=0.00010210465552518144
step=400 loss=0.00016413693083450198
step=410 loss=0.00010884729272220284
step=420 loss=0.00010439904872328043
step=430 loss=0.00014752228162251413
step=440 loss=0.00011902432743227109
step=450 loss=9.99133990262635e-05
step=460 loss=9.923087782226503e-05
step=470 loss=8.425781561527401e-05
step=480 loss=9.92306595435366e-05
step=490 loss=8.330534910783172e-05
plt.plot(test_mse)
plt.yscale("log")