Time series generative model#
This experiment follows the Section 4.1 of Deep Signature Transforms paper.
import equinox as eqx
import jax
import matplotlib.pyplot as plt
import optax # https://github.com/deepmind/optax
from nets import create_generative_net
from utils.dataloader import DataLoader
from utils.signature_normalization import normalize_signature
from jax import numpy as jnp
from jax import random as jrandom
from signax.module import SignatureTransform
from utils.brownian_motion import get_bm_noise
from utils.ornstein_uhlenbeck import get_ou_signal
Parameter setup#
random_seed = 1234
random_key = jrandom.PRNGKey(random_seed)
train_batch_size = 2**10
val_batch_size = 2**10
epochs = 300
n_points = 100
train_key, eval_key, signal_key, model_key = jrandom.split(random_key, 4)
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
Create data#
train_dataset = get_bm_noise(
n_points=n_points, num_samples=train_batch_size, random_key=train_key
)
eval_dataset = get_bm_noise(
n_points=n_points, num_samples=val_batch_size, random_key=eval_key
)
signals = get_ou_signal(signal_key, train_batch_size, n_points)
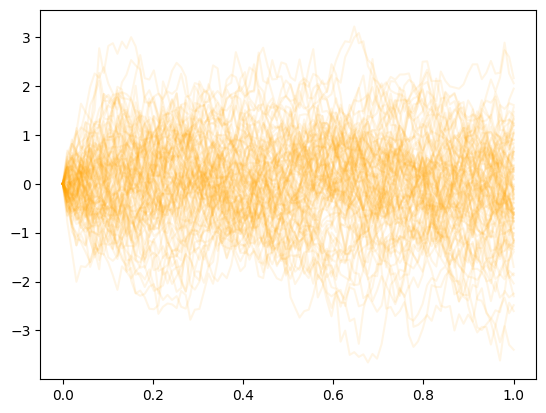
Plot Ornstein-Uhlenbeck data
for sig_path in signals[:100]:
plt.plot(*sig_path, "orange", alpha=0.1)
Create model#
signature_depth = 4
model = create_generative_net(2, key=model_key)
optim = optax.chain(
optax.clip_by_global_norm(1.0),
optax.adam(learning_rate=1e-1),
)
opt_state = optim.init(eqx.filter(model, eqx.is_array))
@eqx.filter_jit
def batch_normalize(batch_generator, batch_data):
"""Normalize signature from generated data"""
return jax.vmap(
lambda _batch: normalize_signature(
batch_generator(_batch),
signature_depth,
)
)(batch_data)
signature_transform = SignatureTransform(signature_depth)
normalized_signal_sigs = batch_normalize(
signature_transform, signals.transpose(0, 2, 1)
)
@eqx.filter_jit
def predict(model_to_predict, path):
path = model_to_predict(path).squeeze()
timeline = jnp.linspace(0, 1, path.shape[0] + 1)
path = jnp.stack([timeline, jnp.concatenate([jnp.array([0]), path])])
path = path.transpose((1, 0))
sig = signature_transform(path)
return sig
def kernel(sigs1, sigs2):
"""Kernel function between two signatures.
This will be used in computing maximum mean discrepancy (MMD)
"""
return jnp.mean(jnp.matmul(sigs1, sigs2.transpose()))
t1 = kernel(normalized_signal_sigs, normalized_signal_sigs)
@eqx.filter_value_and_grad
def loss(model_to_train, paths):
generated_sigs = batch_normalize(
lambda path: predict(model_to_train, path),
paths,
)
t2 = kernel(normalized_signal_sigs, generated_sigs)
t3 = kernel(generated_sigs, generated_sigs)
return jnp.log(t1 - 2 * t2 + t3)
@eqx.filter_jit
def make_step(model_to_train, paths, optimizer_state):
loss_item, grads = loss(model_to_train, paths)
updates, optimizer_state = optim.update(grads, optimizer_state)
model_to_train = eqx.apply_updates(model_to_train, updates)
return loss_item, model_to_train, optimizer_state
Performing optimization#
for step in range(epochs):
train_dataloader = DataLoader(
train_dataset.transpose(0, 2, 1),
batch_size=train_batch_size,
random_key=train_key,
)
for train_datum in train_dataloader:
loss_val, model, opt_state = make_step(
model,
train_datum,
opt_state,
)
if step % 100 == 0:
print(f"step={step} \t loss={loss_val}")
step=0 loss=0.4924733638763428
step=100 loss=-4.107013702392578
step=200 loss=-5.374304294586182
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[11], line 8
2 train_dataloader = DataLoader(
3 train_dataset.transpose(0, 2, 1),
4 batch_size=train_batch_size,
5 random_key=train_key,
6 )
7 for train_datum in train_dataloader:
----> 8 loss_val, model, opt_state = make_step(
9 model,
10 train_datum,
11 opt_state,
12 )
13 if step % 100 == 0:
14 print(f"step={step} \t loss={loss_val}")
File ~/checkouts/readthedocs.org/user_builds/signax/envs/stable/lib/python3.11/site-packages/equinox/_jit.py:107, in _JitWrapper.__call__(self, *args, **kwargs)
106 def __call__(self, /, *args, **kwargs):
--> 107 return self._call(False, args, kwargs)
File ~/checkouts/readthedocs.org/user_builds/signax/envs/stable/lib/python3.11/site-packages/equinox/_jit.py:103, in _JitWrapper._call(self, is_lower, args, kwargs)
101 out = self._cached(dynamic, static)
102 else:
--> 103 out = self._cached(dynamic, static)
104 return _postprocess(out)
File ~/checkouts/readthedocs.org/user_builds/signax/envs/stable/lib/python3.11/site-packages/equinox/_module.py:307, in _unflatten_module(cls, aux, dynamic_field_values)
297 aux = _FlattenedData(
298 tuple(dynamic_field_names),
299 tuple(static_field_names),
(...)
302 tuple(wrapper_field_values),
303 )
304 return tuple(dynamic_field_values), aux
--> 307 def _unflatten_module(cls: type["Module"], aux: _FlattenedData, dynamic_field_values):
308 module = object.__new__(cls)
309 for name, value in zip(aux.dynamic_field_names, dynamic_field_values):
KeyboardInterrupt:
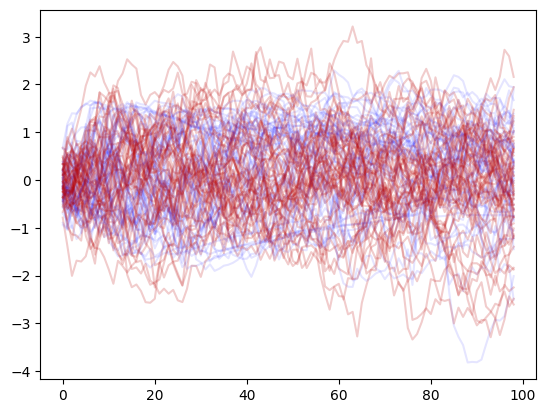
Visualize between data and generated samples
eval_predicted = jax.vmap(lambda datum: model(datum))(
eval_dataset.transpose(0, 2, 1)
).transpose(0, 2, 1)
plt.plot(eval_predicted[50:100, 0].T, "b", alpha=0.1)
plt.plot(signals[50:100, 1, 1:].T, "#ba0404", alpha=0.2);